In data science and machine learning, the bias-variance tradeoff is one of the most important concepts to understand when building predictive models. It helps you find the right balance between a model that learns too little and one that learns too much. Getting this balance right can make the difference between a model that performs well on real data and one that fails to generalize. Learn these essential concepts and more by enrolling in the Data Science Course in Trivandrum at FITA Academy and start building models that truly perform.
What is Bias?
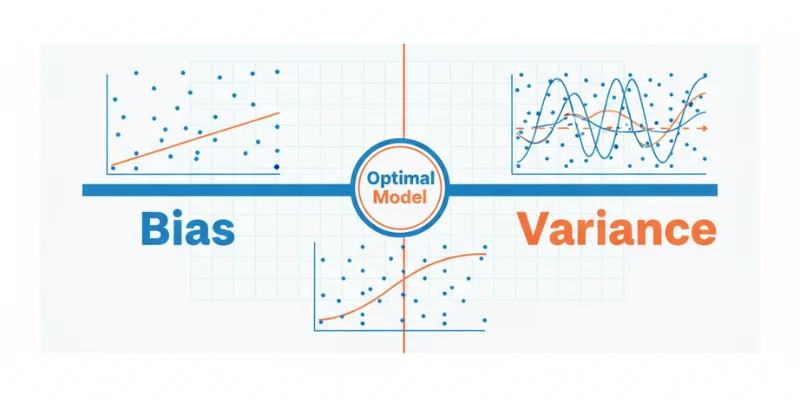
Bias indicates the mistake that happens when a model relies on excessively simplistic assumptions regarding the data. A high-bias model tends to underfit the data because it cannot capture the true patterns or complexity of the underlying relationship.
For example, using a straight line to predict a complex, curved pattern will result in high bias. The model will miss important details, leading to poor accuracy both on the training data and new data.
In short, high bias means the model is too rigid. It does not learn enough from the data.
What is Variance?
Variance refers to the inaccuracies that arise when a model is overly responsive to minor fluctuations in the training data. A high-variance model learns not only the real patterns but also the noise in the data. This results in overfitting, where the model excels on the training data but struggles with new, unseen data. To learn how to manage variance and other core machine learning concepts, join the Data Science Course in Kochi and start building models that generalize effectively.
Imagine trying to fit a very complex curve through every single point in your dataset. While it might look perfect on your training set, it will likely fail on new samples because it memorized the data instead of learning from it.
Understanding the Tradeoff
The bias-variance tradeoff describes the balance between these two types of error.
- High bias and low variance lead to underfitting.
- Low bias and high variance lead to overfitting.
The goal is to find a middle ground where both bias and variance are minimized enough to achieve good overall performance. In this balanced state, the model captures meaningful patterns while ignoring random noise.
This balance ensures that your model generalizes well, meaning it performs consistently on both the training data and new data it has never seen before. Learn more about building models that generalize effectively by enrolling in the Data Science Course in Pune.
Why the Tradeoff Matters
Understanding and managing the bias-variance tradeoff is essential for building reliable machine learning models. If the bias is too high, your predictions will be too simplistic. If the variance is too high, your model becomes unstable.
Data scientists use techniques like cross-validation, regularization, and proper model selection to manage this tradeoff. The key is not to aim for zero error but to find the level of complexity that delivers the best performance on unseen data.
The bias-variance tradeoff is a core concept that shapes every decision in machine learning. It reminds us that a perfect model on training data does not always mean a smart model in real-world situations.
By grasping the relationship between bias and variance, you can develop models that are both precise and dependable, gaining just the right amount of insight from data to generate significant predictions. Take your skills further by joining the Data Science Course in Jaipur.
Also check: What Is the ROC Curve? Interpreting Model Performance
